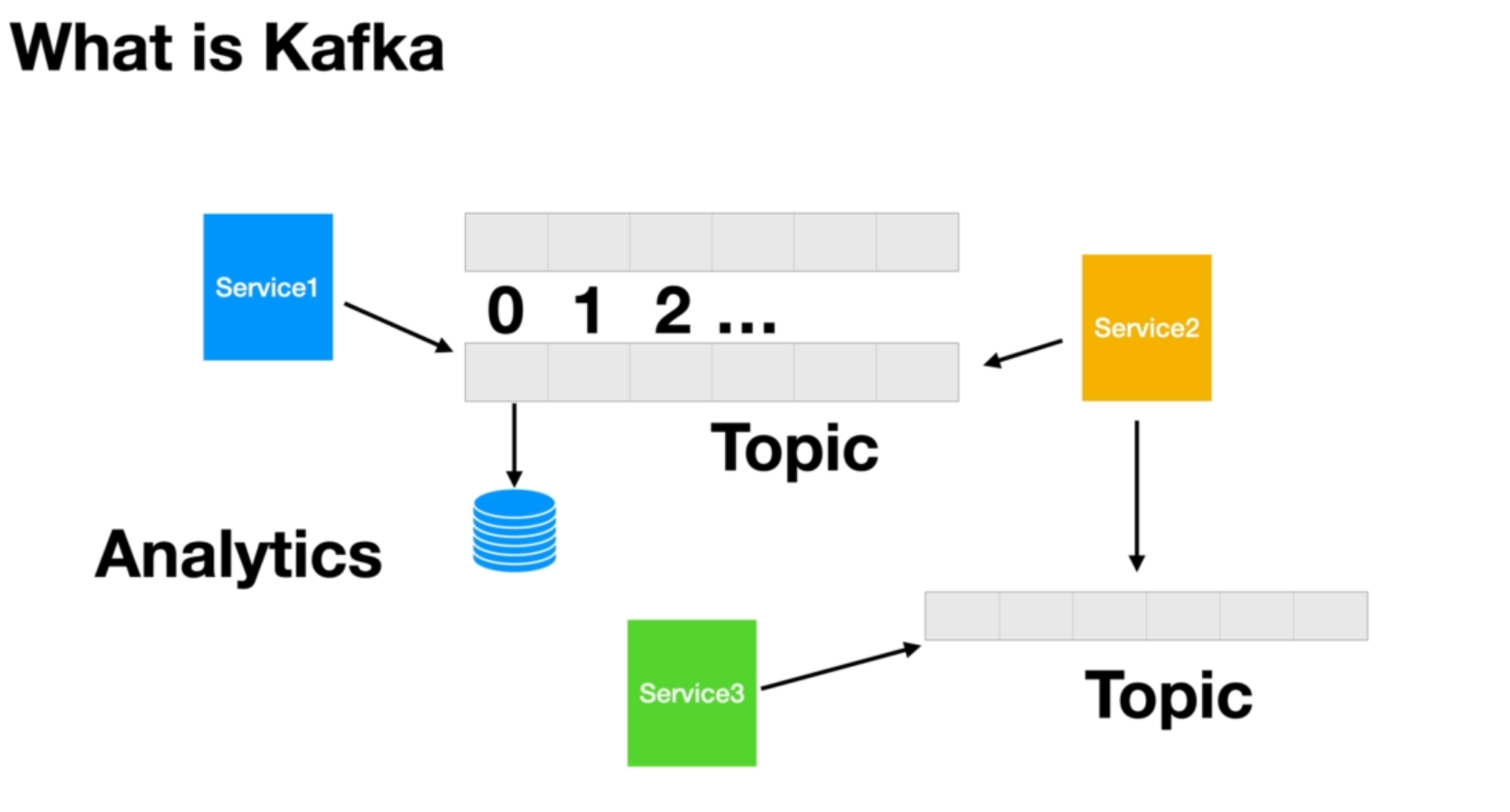
Kafka can have various definitions, depending on how we are using it, but one popular definition is that Kafka is a distributed commit log as events happen in a microservice application. These microservices applications put these events onto a log.
Kafka is a system for managing these logs. The famous and popular term for these logs is a topic. Kafka stores the events in an orderly fashion, and it also writes those to a disk, not just one disk. It can replicate them across disks to ensure that the messages or events are not lost.
Microservice applications exchange events through these topics or streams in real-time. And since the data and event can be processed as soon as they are produced, we can have Real-Time Analytics and make decisions based on these analytics.
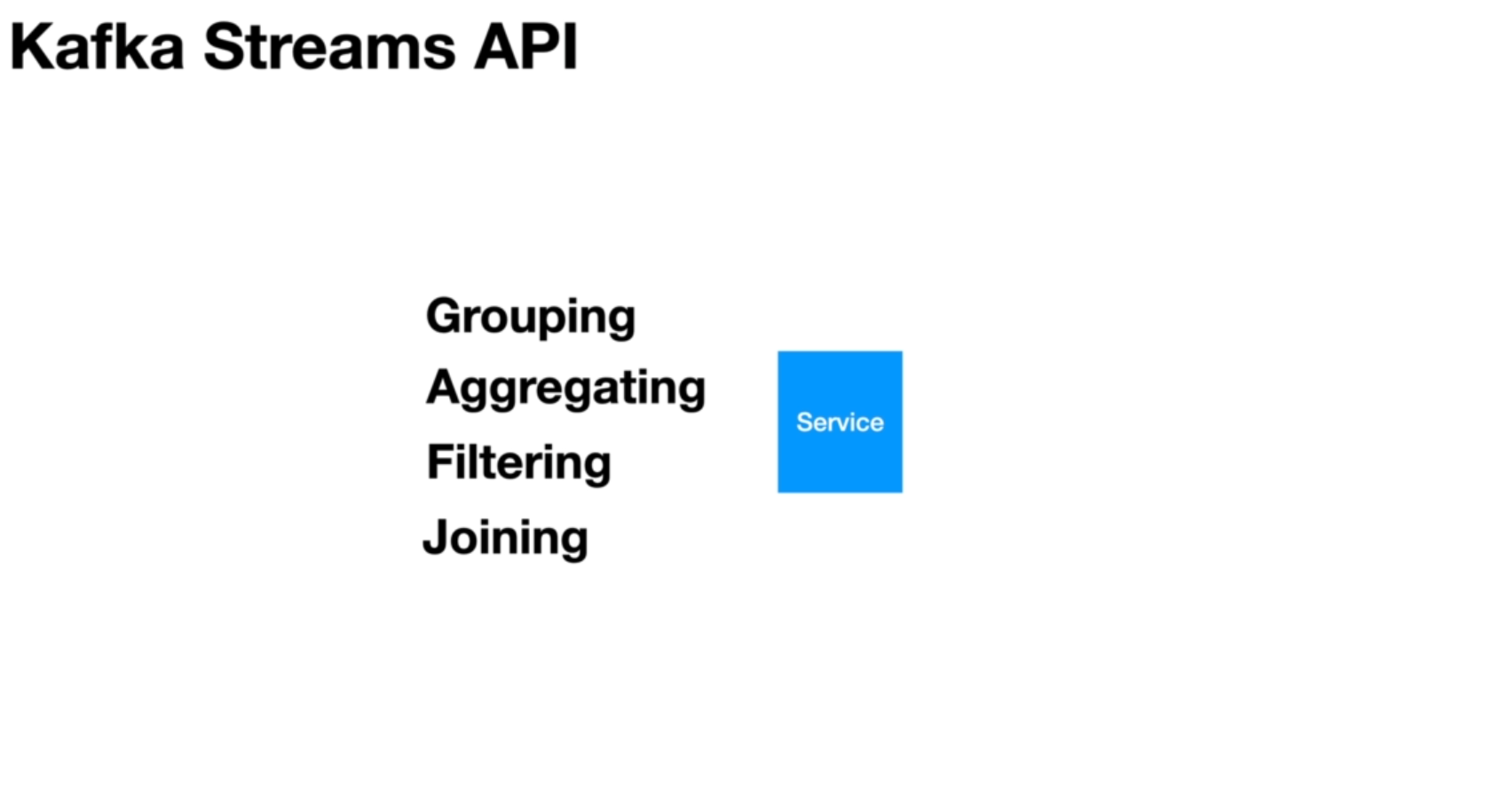
These Microservice applications will have their own processing logic. They don't just read the events from the topic and send them to another topic. They will define their own computational logic.
That is where Kafka comes with the streaming API. The Microservice applications need to group data, aggregate them, filter them, join them, and perform other operations. Kafka provides a streaming API that is super simple to use and allows us to perform these operations out of the box in our Microservices.
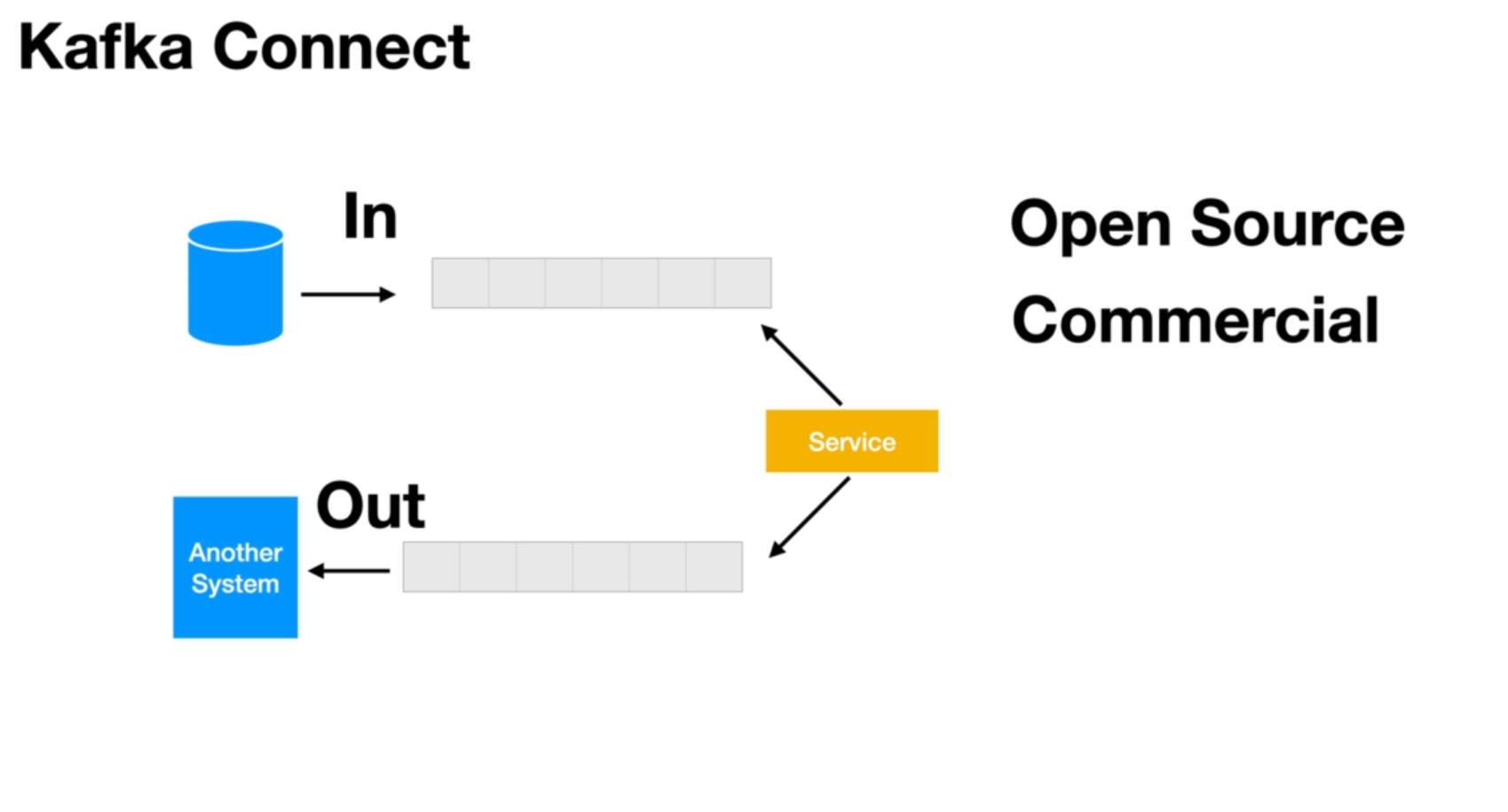
Last but not least, if there is data related to our applications in external databases or other systems, we can use Kafka Connect. Kafka Connect can be easily configured and eliminates the need for writing code. There are hundreds of open source Kafka connectors available that can integrate with other data sources or databases, allowing us to fetch data into Kafka or send data from Kafka to these external sources without writing any code.