In this post, we will explore the advantages of using Kafka and understand why it has gained immense popularity in the world of distributed messaging systems.
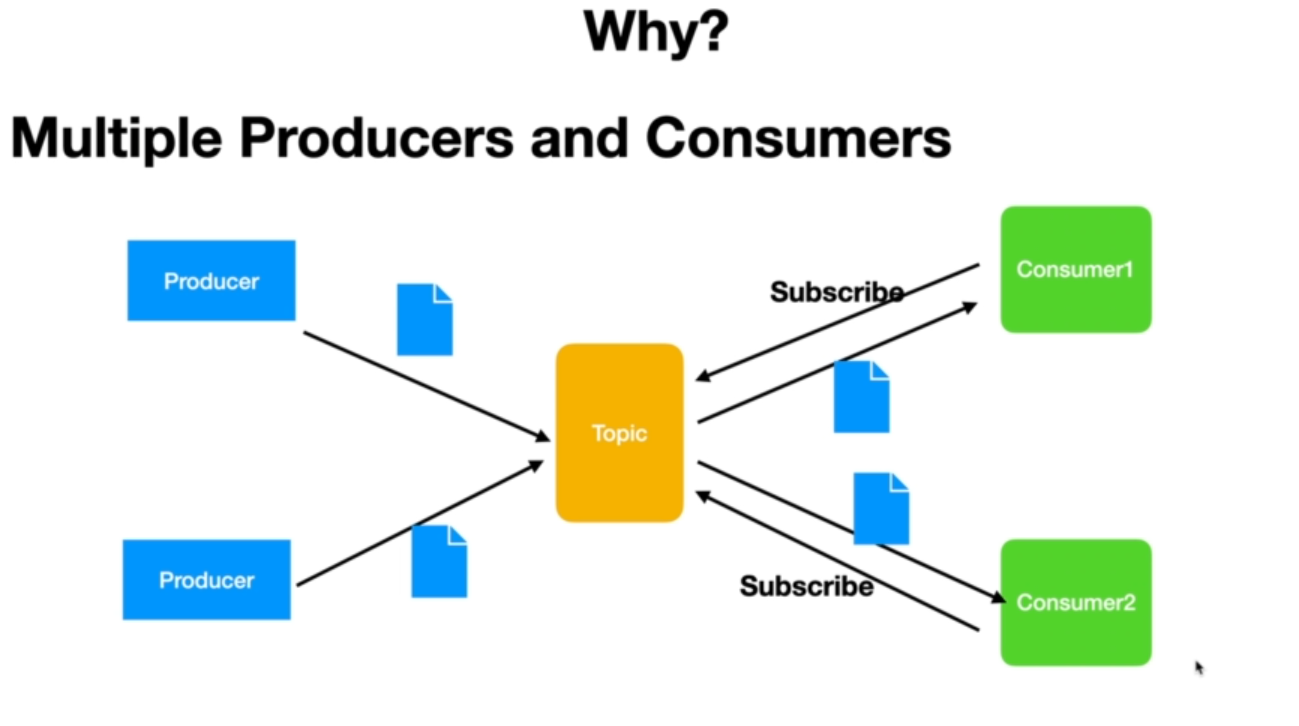
Multiple Producers and Consumers:
One of the key advantages of Kafka is its support for multiple producers and consumers. Unlike traditional messaging systems, Kafka allows multiple producers to write to a single topic simultaneously, and multiple consumers can subscribe and consume messages from the same topic. Additionally, Kafka retains the messages even after consumption, enabling another consumer application to access and process the same message in its own way.
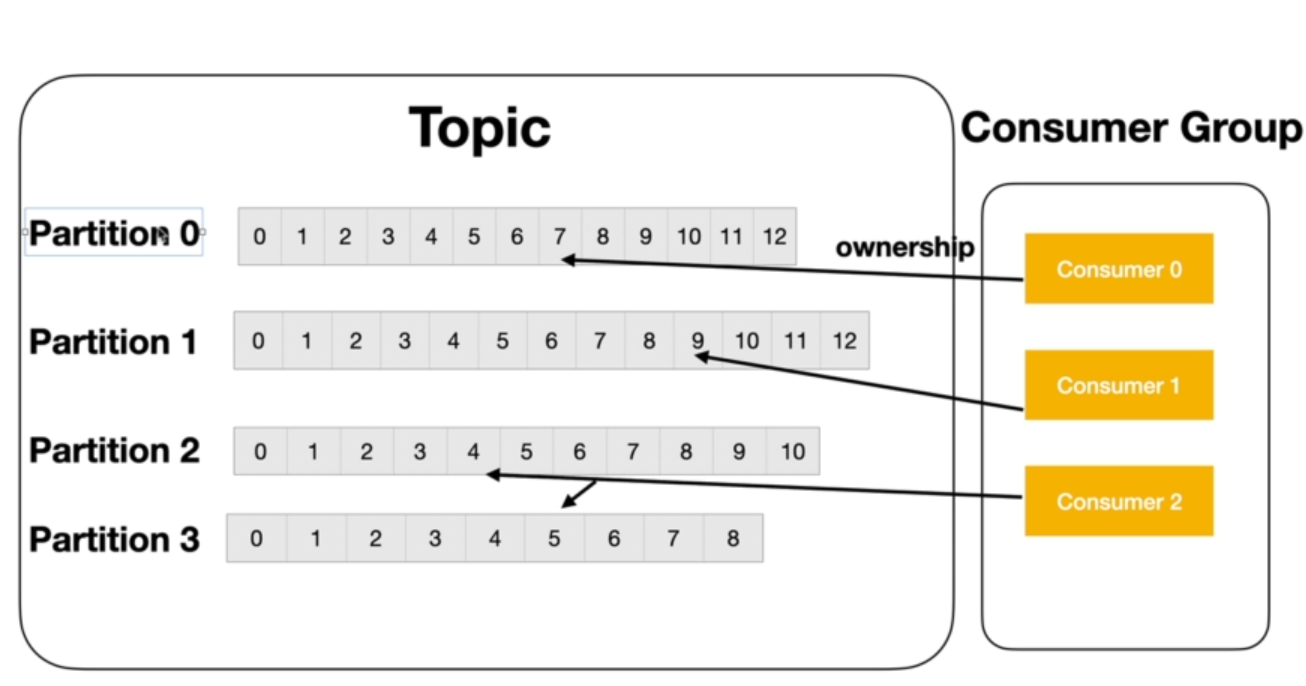
Consumer Groups and Partitions:
Kafka supports consumer groups and partitions, enabling parallel processing within a consumer application. Consumer groups consist of parallel consumers that can run together, and topics are divided into multiple partitions. Messages from producers are distributed across these partitions, allowing for efficient parallel processing. Kafka ensures that within a consumer group, each message is consumed only once, preventing duplication.
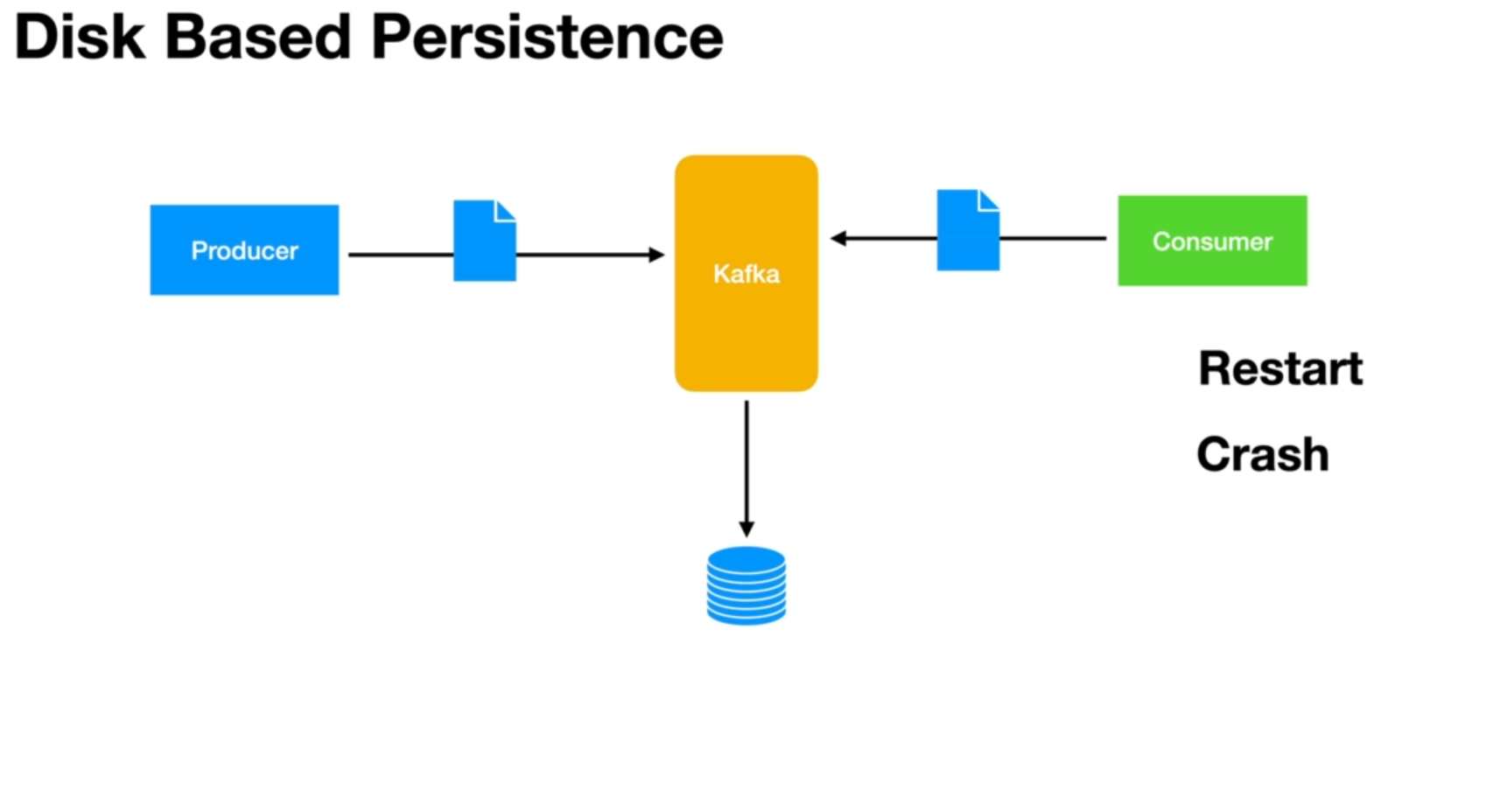
Disk-based Persistence:
Another advantage of Kafka is its disk-based persistence. Even if a consumer temporarily goes down due to a restart or crash, Kafka retains the messages in disk storage for a configurable amount of time. When the consumer comes back up, it can retrieve the messages that were persisted on disk, ensuring data availability and reliability.
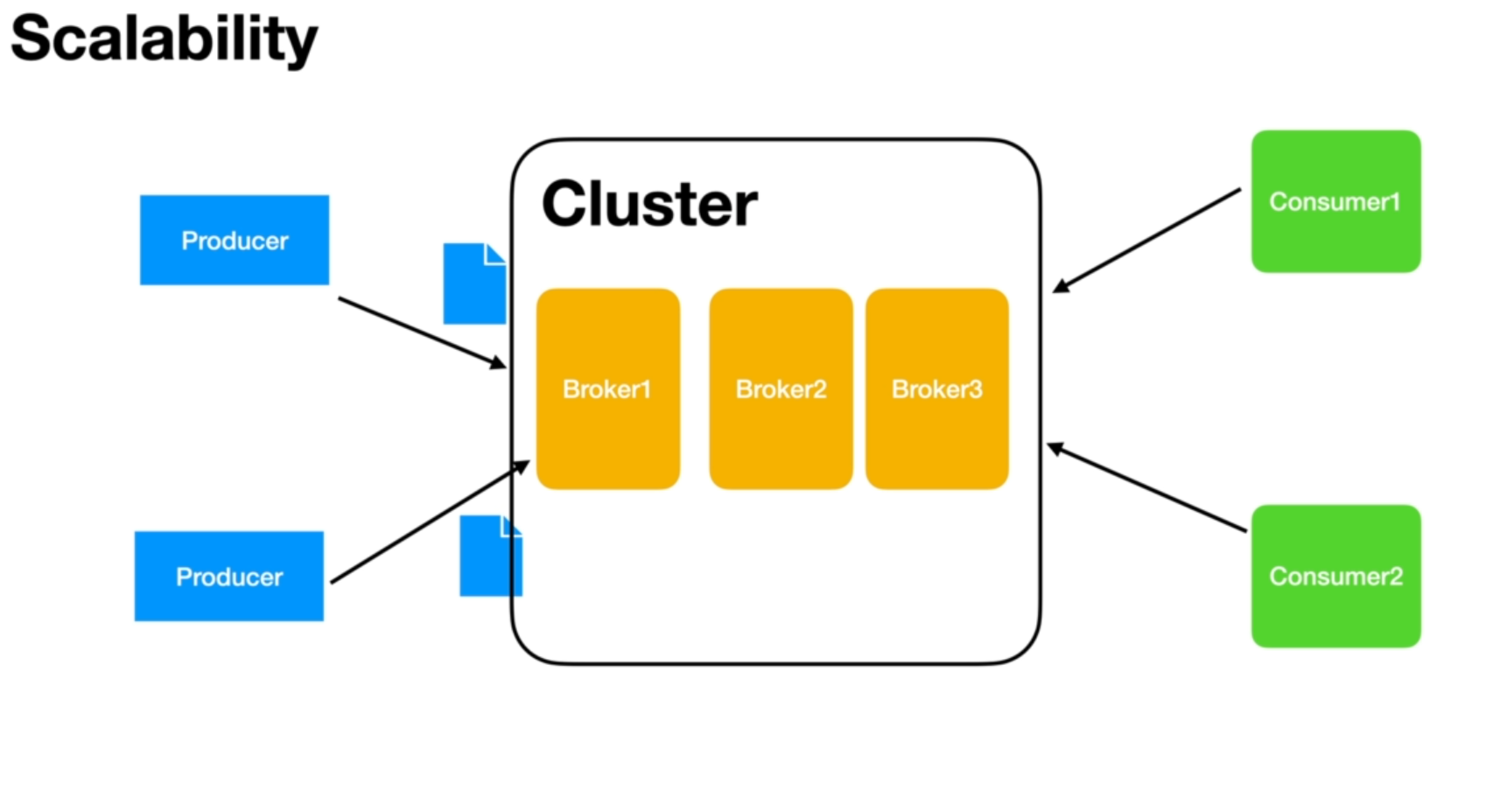
Scalability:
Kafka provides excellent scalability. As the load on the Kafka broker increases, it can be easily scaled up by adding more brokers. In a development or testing environment, a single broker may suffice, but in production environments, clusters of hundreds or even thousands of brokers can be deployed. If one broker goes down, another broker seamlessly takes over, ensuring high availability.
Performance:
Due to its various advantages such as support for multiple producers and consumers, parallel processing through consumer groups and partitions, and scalability, Kafka offers exceptional performance. These features contribute to improved throughput and reduced latency, making Kafka a preferred choice for high-performance data streaming applications.
Conclusion:
Kafka's popularity can be attributed to its numerous advantages that set it apart from traditional messaging systems. With support for multiple producers and consumers, consumer groups and partitions, disk-based persistence, scalability, and high-performance characteristics, Kafka provides a robust and efficient solution for building distributed, real-time data streaming applications.
Note: In subsequent lectures, we will delve deeper into topics such as partitions and consumer groups to gain a comprehensive understanding of Kafka's capabilities.