GitHub Actions is a powerful tool for CI/CD, which gives developers the ability to directly automate workflows from their repositories. The ability to run jobs either in parallel or sequentially is one of its strong points. Mastering when and how to use these modes can considerably improve your pipeline's efficiency.
In this blog, we’ll explore how to use parallelism and sequential execution in a real-world scenario. For our demonstration, we’ll use a workflow from the Mr. Market NEPSE platform to deploy applications to multiple servers.
Problem Identification:
We are spinning up three servers for our application, following a producer-consumer pattern. The Main Server produces jobs, while all servers consume the jobs, sharing the same codebase. Initially, the naive approach required manually going to each server to pull the code and complete the necessary updates. This process was taking up too much of my time.
My First approach was to do sequential GitHub action jobs execution with following rules
Job Dependency Rules
deploy-second-server and deploy-third-server both depend on the successful completion of deploy-main-server .- The
deploy-main-server runs independently.
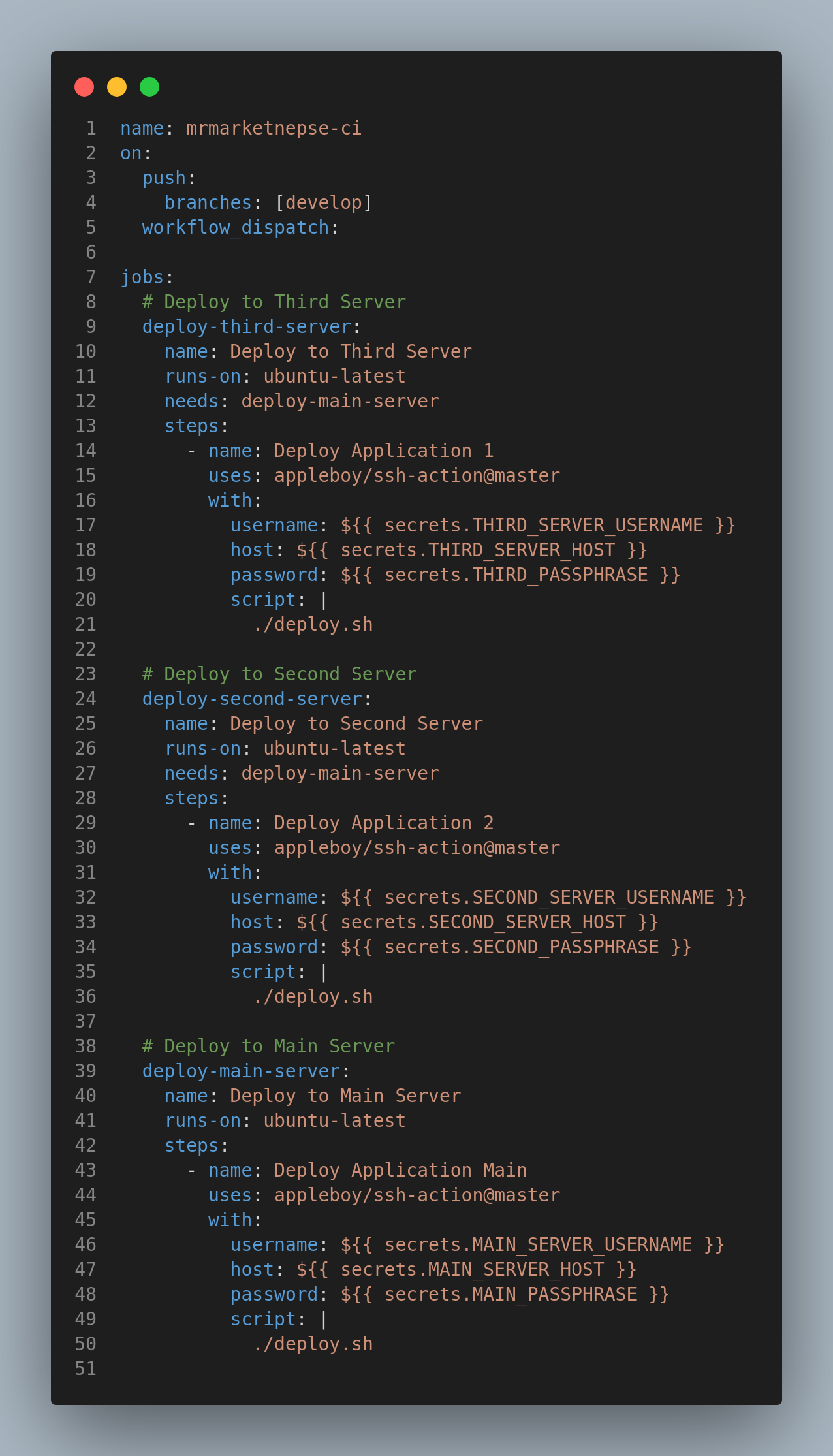
To understand this setup, it’s important to grasp the needs: syntax.
jobs.<job_id>.needs specifies any jobs that must complete successfully before the current job will run.
Problem:
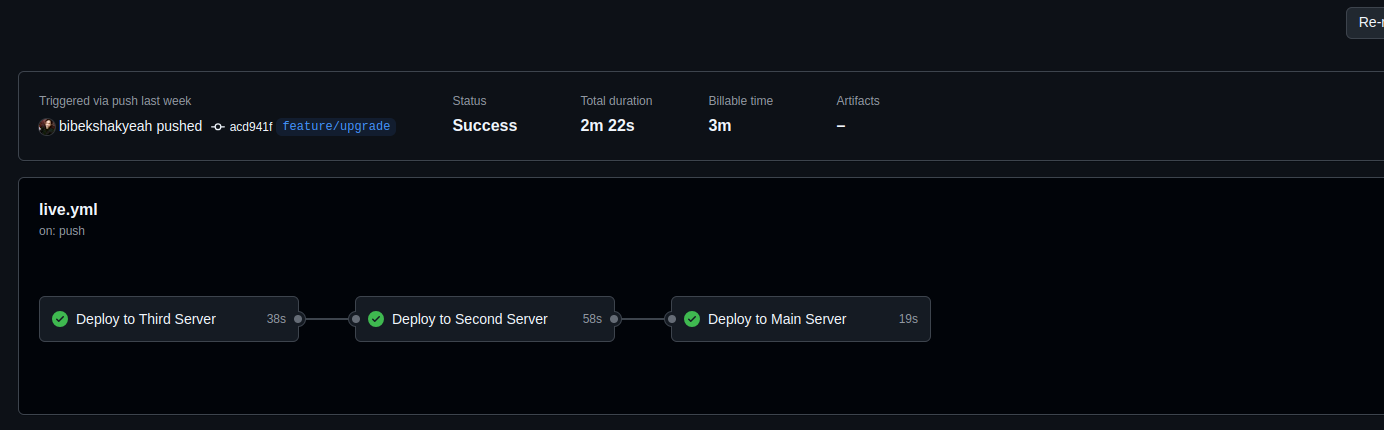
While sequential execution ensures the proper order, it introduced another issue: some old code was still running on the other two servers, which caused exceptions. This was due to the delay in updating the Second and Third Servers, as they were waiting for the Main Server to complete.
Sequential Execution from github
Parallel Execution from github
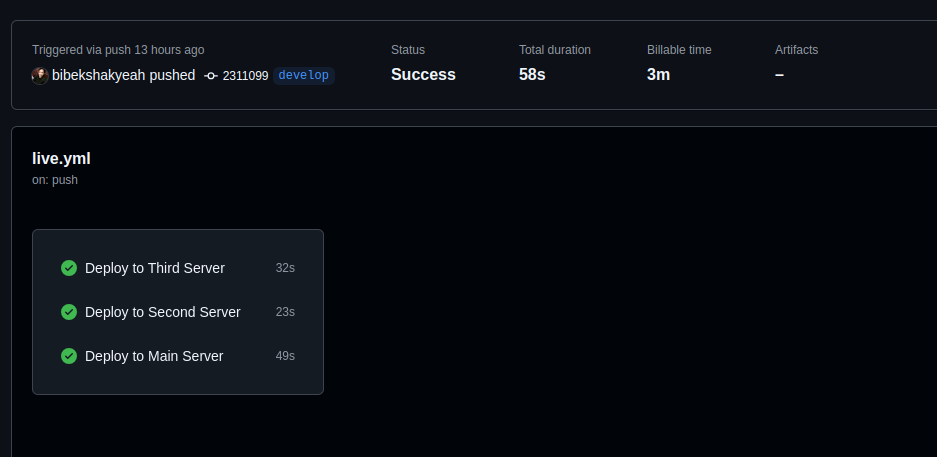
I will try to cover about Matrix strategy in my next post.