What is Batch Processing and How Does it Work?
Batch processing is a method of processing large volumes of data in a systematic and automated way, without requiring human intervention. It refers to the execution of a series of tasks or jobs as a group. This approach is widely adopted in organizations that handle massive amounts of data on a regular basis.
Batch processing is particularly useful in scenarios such as:
- Reading: Fetching data from files, databases, or APIs.
- Transforming: Performing calculations, validations, or aggregations on large datasets.
- Writing: Saving results to files, databases, or external systems.
Note: Batch processing is automated, efficient, and designed for scenarios where speed and scalability are critical.
Where is Batch Processing Used?
Let’s consider a real-world example in the banking domain:
Imagine a banking application processing millions of transactions daily across branches nationwide. Each branch maintains its localized database, which needs to synchronize with the central data center periodically.
For instance:
Every night at midnight, the system needs to update all transactions from branch databases into the centralized database.
Manually processing these transactions or inserting records one by one would take hours, if not days.
With batch processing, these transactions can be processed in parallel, transforming and loading them into the central database in minutes or seconds.
Batch Processing Architecture
To understand how batch processing works, let’s look at its architecture and the roles of its key components. Below is a simplified architecture of batch processing:
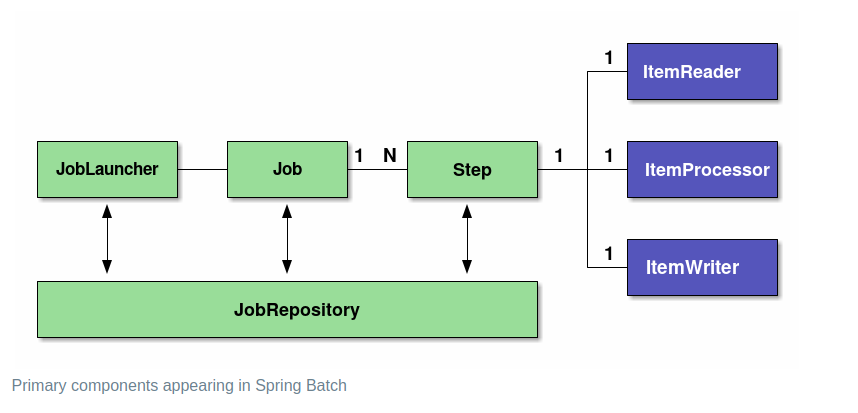
Key Components
1. JobLauncher
- What It Does: Acts as the entry point to trigger a batch job.
- How It Works: The JobLauncher starts the job by passing in the job and any required parameters.
- Purpose: Ensures that the batch job is initiated correctly.
2. Job
- What It Does: Represents the entire batch processing task.
- How It Works: A Job is a container for one or more steps, orchestrating the overall batch execution.
- Purpose: Organizes the processing flow and manages the lifecycle of the job.
3. Step
- What It Does: A step is a single, logical phase of the batch job.
- How It Works: Each step includes a Reader, Processor, and Writer to perform specific tasks.
- Purpose: Divide the batch job into smaller, manageable units that can be executed independently.
4. ItemReader
- What It Does: Reads the input data.
- How It Works: Fetches data from sources like files, databases, or APIs.
- Purpose: Provides raw data to be processed by the Processor.
5. ItemProcessor
- What It Does: Processes and transforms data.
- How It Works: Applies business logic, validations, or transformations to the data.
- Purpose: Converts raw input data into the desired format.
6. ItemWriter
- What It Does: Writes processed data to an output destination.
- How It Works: Saves the processed data into a database, file, or any other system.
- Purpose: Output the final result of the batch processing.
7. JobRepository
- What It Does: Stores metadata about jobs and their executions.
- How It Works: Tracks job status, parameters, execution history, and restart information.
- Purpose: Enables job monitoring, auditing, and restarting in case of failure.
This is the foundation of batch processing architecture and how it simplifies the management of large-scale data operations. With its ability to automate, scale, and optimize data processing, batch processing is an indispensable tool for modern enterprises. Frameworks like Spring Batch make it easy to implement this architecture efficiently, ensuring reliability and scalability for high-volume tasks.